


1.介紹
Numba 是 python 的即時(Just-in-time)編譯器,即當你調用 python 函數時,你的全部或部分代碼就會被轉換為“即時”執行的機器碼,它將以你的本地機器碼速度運行!它由 Anaconda 公司贊助,并得到了許多其他組織的支持。
在 Numba 的幫助下,你可以加速所有計算負載比較大的 python 函數(例如循環)。它還支持 numpy 庫!所以,你也可以在你的計算中使用 numpy,并加快整體計算,因為 python 中的循環非常慢。你還可以使用 python 標準庫中的 math 庫的許多函數,如 sqrt 等。有關所有兼容函數的完整列表,請查看 此處。
2.為什么選擇 Numba?
那么,當有像 cython 和 Pypy 之類的許多其他編譯器時,為什么要選擇 numba?
原因很簡單,這樣你就不必離開寫 python 代碼的舒適區。是的,就是這樣,你根本不需要為了獲得一些的加速來改變你的代碼,這與你從類似的具有類型定義的 cython 代碼獲得的加速相當。那不是很好嗎?
你只需要添加一個熟悉的 python 功能,即添加一個包裝器(一個裝飾器)到你的函數上。類的裝飾器也在開發中了。
所以,你只需要添加一個裝飾器就可以了。例如:

這仍然看起來像一個原生 python 代碼,不是嗎?
3.如何使用 Numba?
Numba 使用 LLVM 編譯器基礎結構 將原生 python 代碼轉換成優化的機器碼。使用 numba 運行代碼的速度可與 C/C++ 或 Fortran 中的類似代碼相媲美。
以下是代碼的編譯方式:
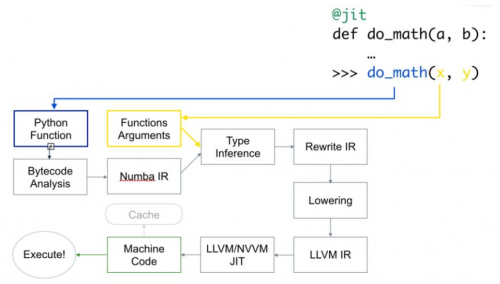
首先,Python 函數被傳入,優化并轉換為 numba 的中間表達,然后在類型推斷(type inference)之后,就像 numpy 的類型推斷(所以 python float 是一個 float64),它被轉換為 LLVM 可解釋代碼。然后將此代碼提供給 LLVM 的即時編譯器以生成機器碼。
你可以根據需要在運行時或導入時 生成 機器碼,導入需要在 CPU(默認)或 GPU 上進行。
4.使用 numba 的基本功能
(只需要加上 @jit !)
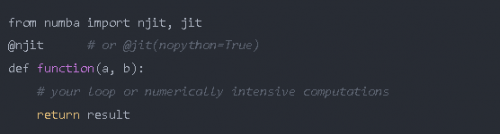
為了獲得最佳性能,numba 實際上建議在你的 jit 裝飾器中加上 nopython=True 參數,加上后就不會使用 Python 解釋器了。或者你也可以使用 @njit。如果你加上 nopython=True的裝飾器失敗并報錯,你可以用簡單的 @jit 裝飾器來編譯你的部分代碼,對于它能夠編譯的代碼,將它們轉換為函數,并編譯成機器碼。然后將其余部分代碼提供給 python 解釋器。
所以,你只需要這樣做:
當使用 @jit 時,請確保你的代碼有 numba 可以編譯的內容,比如包含庫(numpy)和它支持的函數的計算密集型循環。否則它將不會編譯任何東西,并且你的代碼將比沒有使用 numba 時更慢,因為存在 numba 內部代碼檢查的額外開銷。
還有更好的一點是,numba 會對首次作為機器碼使用后的函數進行緩存。因此,在第一次使用之后它將更快,因為它不需要再次編譯這些代碼,如果你使用的是和之前相同的參數類型。
如果你的代碼是 可并行化 的,你也可以傳遞 parallel=True 作為參數,但它必須與 nopython=True 一起使用,目前這只適用于CPU。
你還可以指定希望函數具有的函數簽名,但是這樣就不會對你提供的任何其他類型的參數進行編譯。例如:
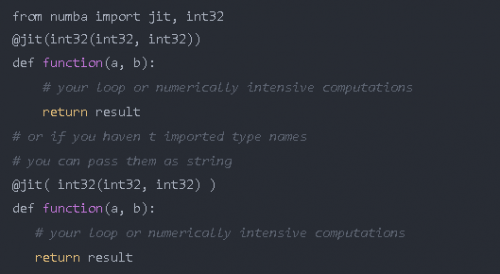
現在你的函數只能接收兩個 int32 類型的參數并返回一個 int32 類型的值。通過這種方式,你可以更好地控制你的函數。如果需要,你甚至可以傳遞多個函數簽名。
你還可以使用 numba 提供的其他裝飾器:
@vectorize:允許將標量參數作為 numpy 的 ufuncs 使用,
@guvectorize:生成 NumPy 廣義上的 ufuncs,
@stencil:定義一個函數使其成為 stencil 類型操作的核函數
@jitclass:用于 jit 類,
@cfunc:聲明一個函數用于本地回調(被C/C++等調用),
@overload:注冊你自己的函數實現,以便在 nopython 模式下使用,例如:@overload(scipy.special.j0)。
Numba 還有 Ahead of time(AOT)編譯,它生成不依賴于 Numba 的已編譯擴展模塊。但:
它只允許常規函數(ufuncs 就不行),
你必須指定函數簽名。并且你只能指定一種簽名,如果需要指定多個簽名,需要使用不同的名字。
它還根據你的CPU架構系列生成通用代碼。
5.@vectorize 裝飾器
通過使用 @vectorize 裝飾器,你可以對僅能對標量操作的函數進行轉換,例如,如果你使用的是僅適用于標量的 python 的 math 庫,則轉換后就可以用于數組。這提供了類似于 numpy 數組運算(ufuncs)的速度。例如:
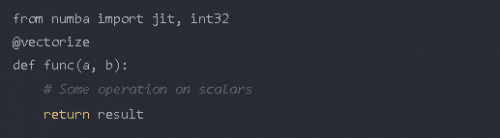
你還可以將 target 參數傳遞給此裝飾器,該裝飾器使 target 參數為 parallel 時用于并行化代碼,為 cuda 時用于在 cudaGPU 上運行代碼。
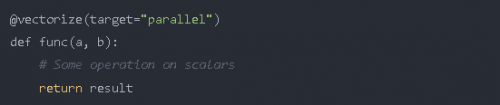
使 target=“parallel” 或 “cuda” 進行矢量化通常比 numpy 實現的代碼運行得更快,只要你的代碼具有足夠的計算密度或者數組足夠大。如果不是,那么由于創建線程以及將元素分配到不同線程需要額外的開銷,因此可能耗時更長。所以運算量應該足夠大,才能獲得明顯的加速。

這個視頻講述了一個用 Numba 加速用于計算流體動力學的Navier Stokes方程的例子:
6.在GPU上運行函數
你也可以像裝飾器一樣傳遞 @jit 來運行 cuda/GPU 上的函數。為此你必須從 numba 庫中導入 cuda。但是要在 GPU 上運行代碼并不像之前那么容易。為了在 GPU 上的數百甚至數千個線程上運行函數,需要先做一些初始計算。實際上,你必須聲明并管理網格,塊和線程的層次結構。這并不那么難。
要在GPU上執行函數,你必須定義一個叫做 核函數 或 設備函數 的函數。首先讓我們來看 核函數。
關于核函數要記住一些要點:
核函數在被調用時要顯式聲明其線程層次結構,即塊的數量和每塊的線程數量。你可以編譯一次核函數,然后用不同的塊和網格大小多次調用它。
核函數沒有返回值。因此,要么必須對原始數組進行更改,要么傳遞另一個數組來存儲結果。為了計算標量,你必須傳遞單元素數組。
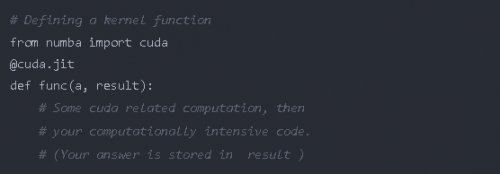
因此,要啟動核函數,你必須傳入兩個參數:
每塊的線程數,
塊的數量。
例如:

每個線程中的核函數必須知道它在哪個線程中,以便了解它負責數組的哪些元素。Numba 只需調用一次即可輕松獲得這些元素的位置。
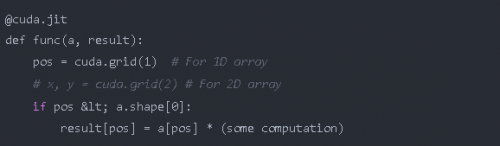
為了節省將 numpy 數組復制到指定設備,然后又將結果存儲到 numpy 數組中所浪費的時間,Numba 提供了一些 函數 來聲明并將數組送到指定設備,如:numba.cuda.device_array,numba.cuda。device_array_like,numba.cuda.to_device 等函數來節省不必要的復制到 cpu 的時間(除非必要)。
另一方面,設備函數 只能從設備內部(通過核函數或其他設備函數)調用。比較好的一點是,你可以從 設備函數 中返

你還應該在這里查看 Numba 的 cuda 庫支持的功能。
Numba 在其 cuda 庫中也有自己的原子操作,隨機數生成器,共享內存實現(以加快數據的訪問)等功能。
ctypes/cffi/cython 的互用性:
cffi – 在 nopython 模式下支持調用 CFFI 函數。
ctypes – 在 nopython 模式下支持調用 ctypes 包裝函數。
Cython 導出的函數是 可調用的。














 京公網安備 11010802030320號
京公網安備 11010802030320號